大消息。
9月29日,DeepSeek宣布,正式发布DeepSeek-V3.2-Exp模型。作为迈向新一代架构的中间步骤,V3.2-Exp在V3.1-Terminus的基础上引入了DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。

据了解,DeepSeek Sparse Attention(DSA)首次实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。
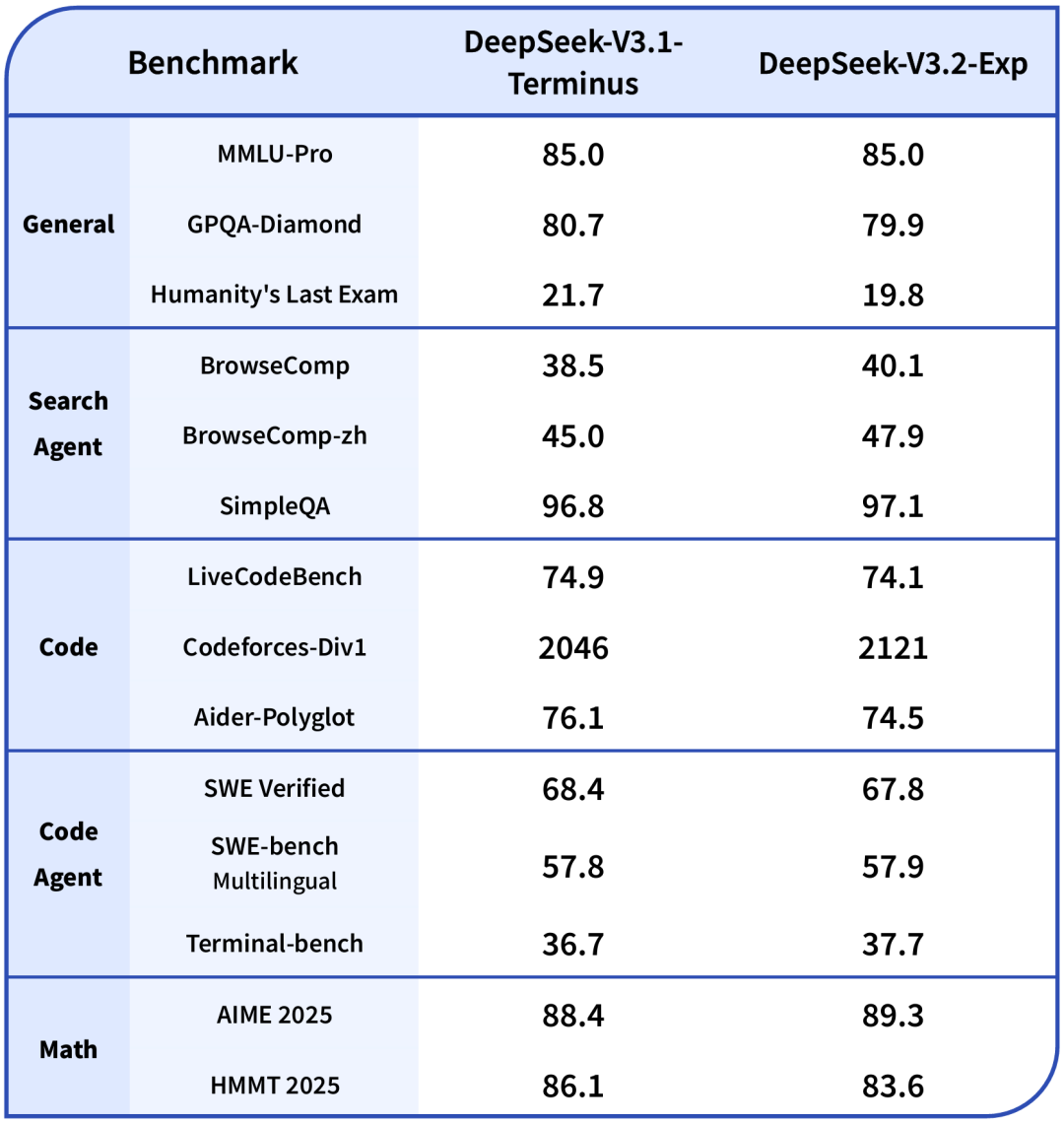
为了严谨地评估引入稀疏注意力带来的影响,DeepSeek特意把DeepSeek-V3.2-Exp的训练设置与V3.1-Terminus进行了严格的对齐。在各领域的公开评测集上,DeepSeek-V3.2-Exp的表现与V3.1-Terminus基本持平。
目前,官方App、网页端、小程序均已同步更新为DeepSeek-V3.2-Exp,同时API大幅度降价。在新的价格政策下,开发者调用DeepSeek API的成本将降低50%以上。

近期,DeepSeek动作不断。9月22日,DeepSeek小助手在官方社群中称,DeepSeek线上模型已升级,当前版本号DeepSeek-V3.1-Terminus。8月21日,DeepSeek正式发布DeepSeek-V3.1,称其为“迈向Agent(智能体)时代的第一步”。据DeepSeek介绍,V3.1主要包含三大变化:一是采用混合推理架构,一个模型同时支持思考模式与非思考模式;二是具有更高的思考效率,能在更短时间内给出答案;三是具有更强的智能体能力,通过后训练优化,新模型在工具使用与智能体任务中的表现有较大提升。
此外,9月17日,在最新一期的国际权威期刊Nature(自然)中,DeepSeek-R1推理模型研究论文登上了封面。该论文由DeepSeek团队共同完成,梁文锋担任通讯作者,首次公开了仅靠强化学习就能激发大模型推理能力的重要研究成果。这是中国大模型研究首次登上Nature封面,也是全球首个经过完整同行评审并发表于权威期刊的主流大语言模型研究,标志着中国AI技术在国际科学界获得最高认可。
Nature在其社论中评价道:“几乎所有主流的大模型都还没有经过独立同行评审,这一空白终于被DeepSeek打破。”
综合自:DeepSeek、证券时报此前报道
责编:李丹
校对:陶谦



