国产AI大模型,提前过年了。
1月20日晚间,月之暗面(Kimi)和深度求索(DeepSeek)这两大备受瞩目的AI大模型创业公司,几乎是同时发布了新模型,并均声称新模型的性能对标OpenAI的o1模型。值得注意的是,在DeepSeek发布新模型后的两小时后,Kimi紧随其后也推出了新模型,颇有些“针锋相对”的意味。
在去年年底DeepSeek爆火之后,这家来自来自杭州、低调又神秘的创业公司赚足世人眼球的同时,也极大地改变了国产大模型创业公司的竞争格局,对国产大模型“六小虎”构成了一定的冲击。作为行业的“鲶鱼”,DeepSeek如今的一举一动都搅动着行业的潮流。进入2025年,国产大模型之间的竞争将变得越来越激烈,一场决定存亡的“决战”已经打枪。
同日发布对标OpenAI o1的新模型
1月20日晚间,深度求索公司正式发布新模型DeepSeek-R1,并同步开源模型权重。据官方介绍,DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。
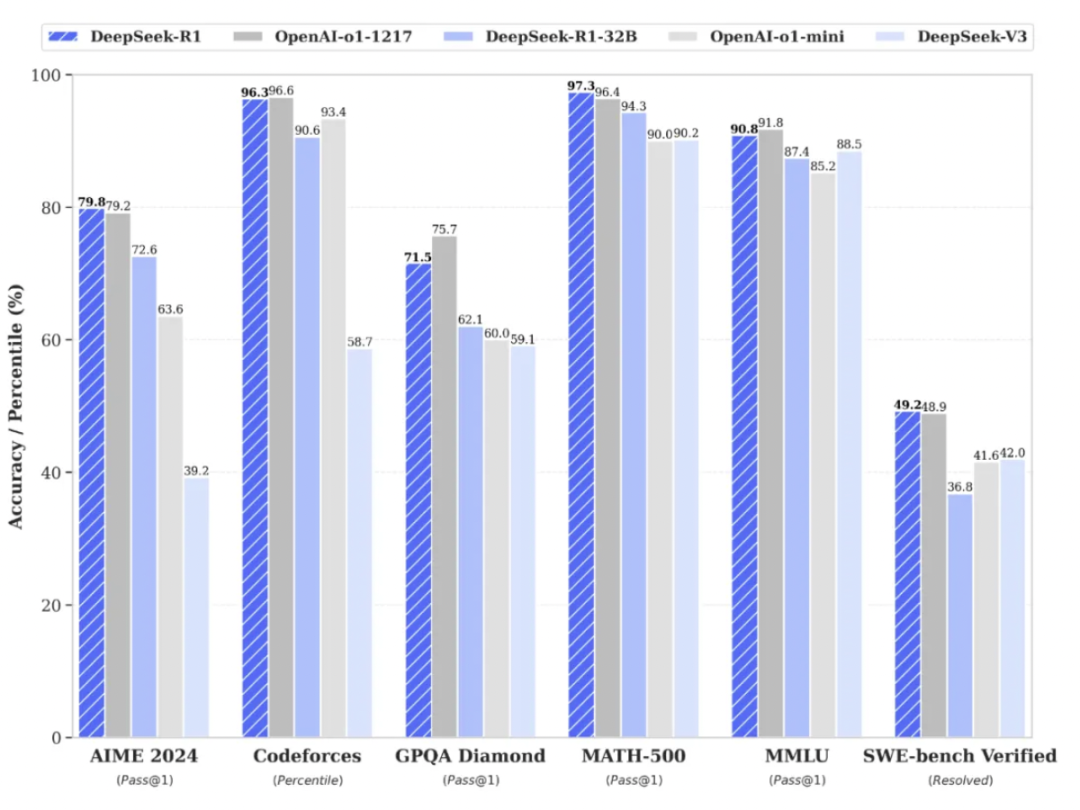
根据其发布的模型性能评测结果,在美国数学竞赛(AMC)中难度等级最高的AIME以及全球顶级编程竞赛(codeforces)等权威评测中,DeepSeek-R1模型成绩与OpenAIo1不相上下,甚至在某些指标小幅超越OpenAIo1模型。与此同时,除了DeepSeek-R1以外,团队还开源了6个由R1模型蒸馏而来的小型模型,其中的32B与70B模型性能也能比肩OpenAI-o1-mini模型。
在API定价方面,DeepSeek延续了一贯的低价风格,输入费用低至每百万tokens1元(缓存命中)/4元(缓存未命中),输出费用仅为每百万tokens16元,整体支出较o1节省96%,这无疑使得Deepseek-R1在成本效益上具备了压倒性的竞争力。
就在DeepSeek-R1发布后的短短两个小时后,月之暗面也发布了k1.5多模态思考模型。据介绍,从基准测试成绩看,k1.5多模态思考模型实现了SOTA(state-of-the-art)级别的多模态推理和通用推理能力。(在科学研究、技术发展和各种专业领域中,“SOTA”,通常用来指代某个领域中最先进的技术或方法。)
具体来看,在short-CoT模式下,Kimik1.5的数学、代码、视觉多模态和通用能力,大幅超越了全球范围内短思考SOTA模型GPT-4o和Claude3.5 Sonnet的水平,领先达到550%;在long-CoT模式下,Kimik1.5的数学、代码、多模态推理能力,也达到长思考SOTA模型OpenAIo1正式版的水平。
国产大模型“六小虎”已变为“七小强”
去年12月26日,深度求索宣布全新系列模型DeepSeek-V3上线并同步开源。这一模型不仅以卓越的性能超越或媲美全球顶级的开源及闭源模型,更重要的是训练成本极低,被称为“AI界的拼多多”,以史无前例的性价比被国内外一众圈内大佬点赞,引发广泛关注。
随着DeepSeek-V3的爆火,其背后的大模型创业公司深度求索也进入了大家的视野。过去的半个多月里,全网都在扒DeepSeek背后的团队,并发现DeepSeek团队最大的特点就是年轻,来自清华北大的应届生在其中非常活跃,核心技术岗位基本以应届和毕业一两年的人为主。因此,这个年轻的、由清北应届生撑起来的公司也被称为“组织形态上最像OpenAI的中国AI公司”。
业内人士分析称,DeepSeek从创立开始就是中国大模型的技术创新者,在大厂和创业公司都在遵循着Llama架构的时候,它选择对模型架构进行了全方位创新,提出的一种崭新的MLA(一种新的多头潜在注意力机制)架构,把显存占用降到了过去最常用的MHA架构的5%—13%,同时独创的DeepSeekMoESparse结构也把计算量降到极致,最终促成了成本的下降。而且与早期的OpenAI类似的是,Deepseek兼具高密度的人才团队和持续创新的精神,因而能持续地给中国大模型带来惊喜。
而事实上,月之暗面也曾被视为“最有可能成为中国OpenAI的公司”。去年年初,月之暗面凭借以长文本为核心优势的Kimi智能助手产品火爆出圈。彼时,头顶着“90后清华校友技术天才创业者”“最强长文本”等诸多光环,月之暗面迅速完成了巨额的融资,吸引一众知名投资机构加持,跻身“200亿元估值俱乐部”,成为国产大模型创业公司的“顶流”。
然而在爆火之后,Kimi因激进的流量投放策略、创始人套现传闻、投资人仲裁风波等事件,屡屡陷入舆论的风口浪尖。与此同时,国产大模型的竞赛在经历了“百模大战”后,尚留在牌桌中的玩家之间的竞争也更趋于激烈。Kimi不仅在流量投放上面临着字节豆包的疯狂进攻,而且竞争对手也纷纷发力长文本能力,Kimi的优势逐渐变得不那么明显。
头顶着“清北应届生”光环的DeepSeek,无疑给包括Kimi在内的国产大模型创业公司带来了压力。业内有人认为,DeepSeek事实上已经可以和“六小虎”(智谱AI、月之暗面、百川智能、Minimax、阶跃星辰、零一万物)并列成为“七小强”。更重要的是,DeepSeek由国内知名量化资管巨头幻方量化创立,未进行过任何融资,特点是“少花钱多办事”,与依靠融资输血、估值水涨船高的其他创业公司相比显得格外另类。
这一低调的技术黑马,无论是技术路线还是发展模式,都走出了一条与众不同的道路,也改变了国产大模型的竞争格局。随着竞争继续向深水区挺进,谁能留在牌桌上笑到最后,或许能在2025年见分晓。
校对:祝甜婷



